AI/ML
Build, deploy, lead, teach, gain mastery and influence people in the field of Artificial Intelligence and its application across teams and businesses to bring about transformations with visionary outcomes.

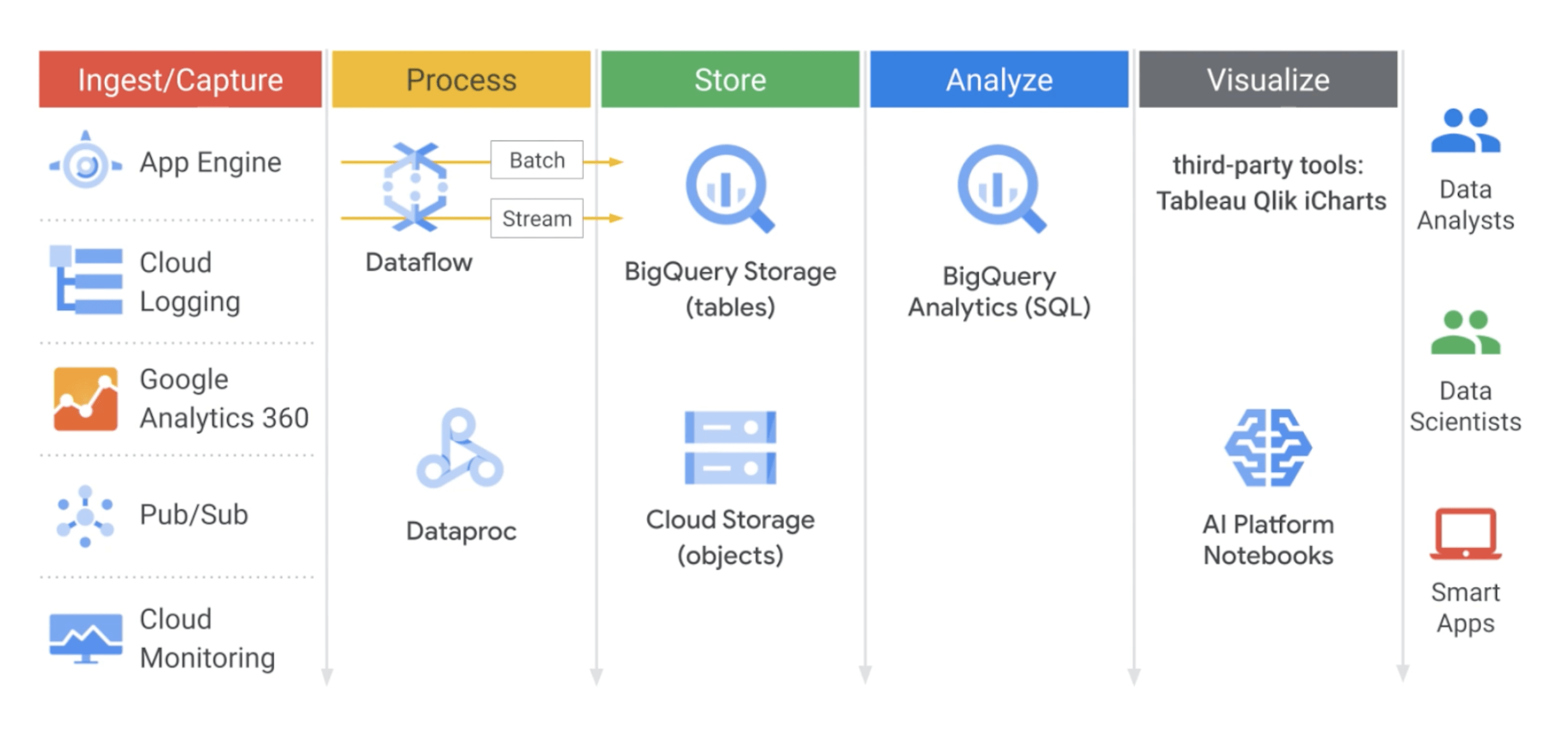
Data Engineering enables data-driven decision making by collecting, transforming, and publishing data models. A data engineer is able to design, build, operationalize, secure, and monitor data processing systems with a particular emphasis on security and compliance; scalability and efficiency; reliability and fidelity; and flexibility and portability.
Data engineering techniques can reveal trends and metrics that would otherwise be lost in the mass of information. This information can then be used to optimize processes to increase the overall efficiency of a business or system.
Products
Cloud Storage, Pub/Sub, Dataprep, Dataflow, DataProc, BigQuery, BQ BI Engine, Looker, Data Studio, AI Platform Notebooks
If your business doesn’t rely on data to solve problems, build revenue or track capital, then you will lose a lot
Close to 82% of businesses rely on data visualization graphics to portray business related metrics.
If data scientists are life blood of today’s data driven enterprise then data engineers are the veins carrying clean blood for machine learning algorithms to be useful.
Make analytics easier by bringing together data from multiple sources in BigQuery, for seamless analysis. You can upload data files from local sources, Google Drive, or Cloud Storage buckets, take advantage of BigQuery Data Transfer Service (DTS), Data Fusion plug-ins, or leverage Google's industry-leading data integration partnerships. You have ultimate flexibility in how you bring data into your data warehouse.

In computing, a data pipeline is a type of application that processes data through a sequence of connected processing steps. As a general concept, data pipelines can be applied, for example, to data transfer between information systems, extract, transform, and load (ETL), data enrichment, and real-time data analysis. Typically, data pipelines are operated as a batch process that executes and processes data when run, or as a streaming process that executes continuously and processes data as it becomes available to the pipeline.

Google’s stream analytics makes data more organized, useful, and accessible from the instant it’s generated. Built on Pub/Sub along with Dataflow and BigQuery, our streaming solution provisions the resources you need to ingest, process, and analyze fluctuating volumes of real-time data for real-time business insights. This abstracted provisioning reduces complexity and makes stream analytics accessible to both data analysts and data engineers.

Pub/Sub is a messaging and ingestion for event-driven systems and streaming analytics. Scalable, in-order message delivery with pull and push modes, Auto-scaling and auto-provisioning with support from zero to hundreds of GB/second, Independent quota and billing for publishers and subscribers, Global message routing to simplify multi-region systems.1
At-least-once delivery
Synchronous, cross-zone message replication and per-message receipt tracking ensures at-least-once delivery at any scale.
Exactly-once processing
Dataflow supports reliable, expressive, exactly-once processing of Pub/Sub streams.
Google Cloud–native integrations
Take advantage of integrations with multiple services, such as Cloud Storage and Gmail update events and Cloud Functions for serverless event-driven computing.
Dataprep by Trifacta is an intelligent data service for visually exploring, cleaning, and preparing structured and unstructured data for analysis, reporting, and machine learning. 1
Predictive transformation
Dataprep uses a proprietary inference algorithm to interpret the data transformation intent of a user’s data selection.
Active profiling
See and explore your data through interactive visual distributions of your data to assist in discovery, cleansing, and transformation.
Data pipeline orchestration
Schedule and automate your data preparation jobs by chaining them together in sequential and conditional order.
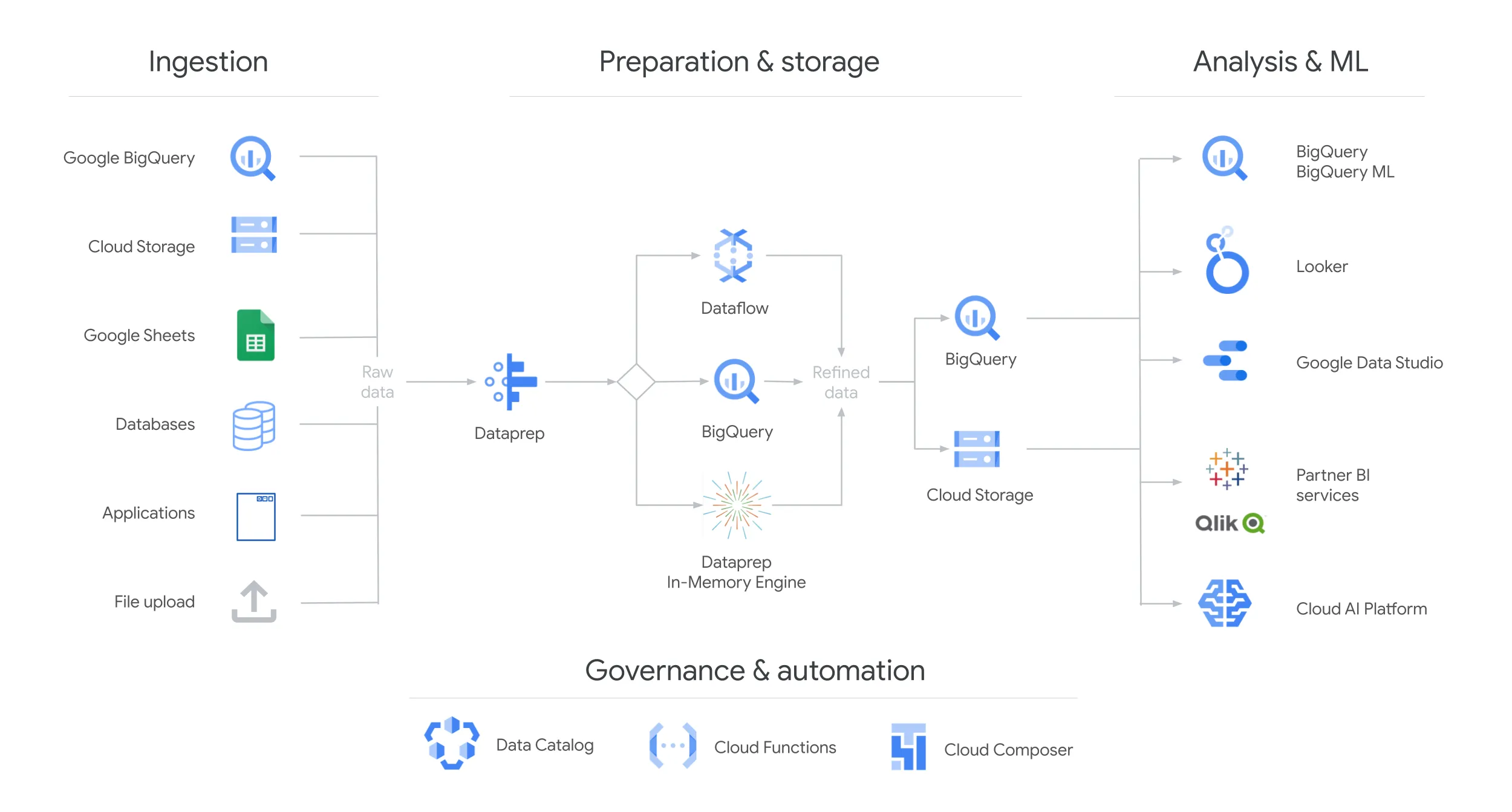
Dataproc is a fully managed and highly scalable service for running Apache Spark, Apache Flink, Presto, and 30+ open source tools and frameworks. Use Dataproc for data lake modernization, ETL, and secure data science, at planet scale, fully integrated with Google Cloud, at a fraction of the cost.1
Modernize your open source data processing
Whether you need VMs or Kubernetes, extra memory for Presto, or even GPUs, Dataproc can help accelerate your data and analytics processing by spinning up purpose-built environments on-demand.
Containerize Apache Spark jobs with Kubernetes
Build your Apache Spark jobs using Dataproc on Kubernetes so you can use Dataproc with Google Kubernetes Engine (GKE) to provide job portability and isolation.
Autoscalling, resizable clusters.
Dataproc autoscaling & resizing provides a mechanism for automating cluster resource management and enables automatic addition and subtraction of cluster workers (nodes) & also create and scale clusters quickly with various virtual machine types, disk sizes, number of nodes, and networking options.
Dataflow is a Unified stream and batch data processing that's serverless, fast, and cost-effective. 1
Vertical & horizontal autoscaling
Horizontal autoscaling lets the Dataflow service automatically choose the appropriate number of worker instances required to run your job.
Streaming Engine
Streaming Engine separates compute from state storage and moves parts of pipeline execution out of the worker VMs and into the Dataflow service back end, significantly improving autoscaling and data latency.
Batch Flexible scheduling
For processing with flexibility in job scheduling time, such as overnight jobs, flexible resource scheduling (FlexRS) offers a lower price for batch processing.
Serverless, highly scalable, and cost-effective multicloud data warehouse designed for business agility.1
Serverless
With serverless data warehousing, Google does all resource provisioning behind the scenes, so you can focus on data and analysis rather than worrying about upgrading, securing, or managing the infrastructure.
Multicloud capabilities
BigQuery Omni (Preview) allows you to analyze data across clouds using standard SQL and without leaving BigQuery’s familiar interface.
Built-in ML and AI integrations
Besides bringing ML to your data with BigQuery ML, integrations with Vertex AI and TensorFlow enable you to train and execute powerful models on structured data in minutes, with just SQL.
Looker is an enterprise platform for business intelligence, data applications, and embedded analytics.1
Integrated end-to-end multicloud platform.
Connect, analyze, and visualize data across Google Cloud, Azure, AWS, on-premises databases, or ISV SaaS applications with equal ease at high scale, with the reliability and trust of Google Cloud.
Common data model over all your data.
Operationalize BI for everyone with powerful data modeling that abstracts the underlying data complexity at any scale and helps to create a common data model for the entire organization.
Augmented analytics
Augment business intelligence from Looker with leading-edge artificial intelligence, machine learning, and advanced analytics capabilities built into Google Cloud Platform.

Artificial intelligence leverages computers and machines to mimic the problem-solving and decision-making capabilities of the human mind. At its simplest form, artificial intelligence is a field, which combines computer science and robust datasets, to enable problem-solving. It also encompasses sub-fields of machine learning and deep learning, which are frequently mentioned in conjunction with artificial intelligence. These disciplines are comprised of AI algorithms which seek to create expert systems which make predictions or classifications based on input data.
Artificial Intelligence as a service, or AIaaS, is the on-demand delivery and use of AI and Deep learning capabilities towards an individual or business objective. AIaaS provides cognitive computing capabilities such as language detection, image analysis and detection, text recognition, Natural language processing, facial expression, sentiment analysis etc.
Products
Cloud Storage, BigQuery ML, AI Hub, Data Labeling, Deep Learning VM, AI Platform, TensorFlow Tool, AI Prediction Platform

Digital transformation has gripped the mentality of any business run today. AI services provide the output for that transformation.
Nearly 77% companies around the world have adopted AI-powered service.
If data scientists are life blood of today’s data driven enterprise then data engineers are the veins carrying clean blood for machine learning algorithms to be useful.
Delivering high-performing recommendations across channels
Implement ML models, without writing code
Driving increased customer engagement

Vehicles can produce upwards of 560 GB data per vehicle, per day. This deluge of data represents opportunities to derive value from the continuous stream of data and challenges in processing and analyzing data at this scale. 1
Device Management
To connect devices to any platform, you must be able to authenticate, authorize, push updates, configure, and monitor software. These services must scale to millions of devices and provide persistent availability.
Predictive models
You must have predictive models based on current and historical data in order to predict business-level outcomes.
Data analytics
You can perform complex analysis of time-series data generated from devices to gain insights into events, tolerances, trends, and possible failures

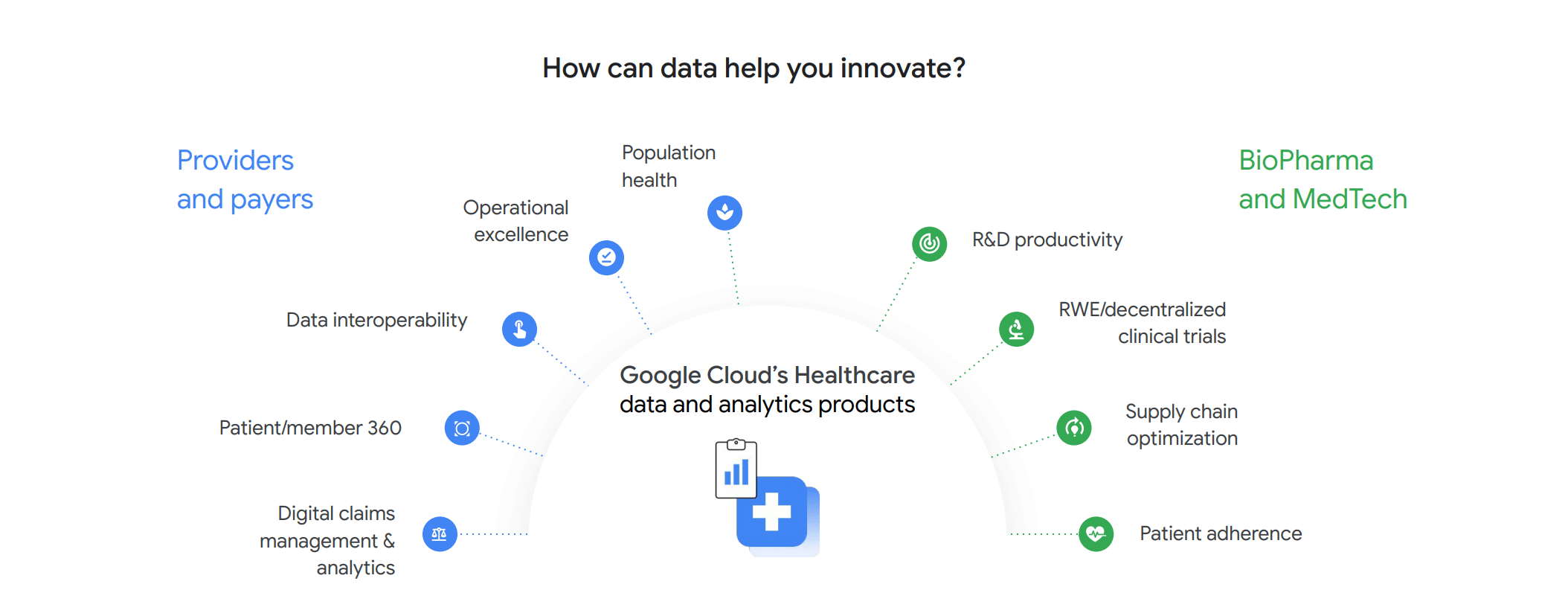
Drive innovation and growth in your organization by unlocking valuable insights from your data 1
Data-driven healthcare future
The sheer volume of data in your organization presents an opportunity to provide deeper insights, distribute them to the right people, and then make better real-time decisions – all with the highest levels of security, compliance, and respect for user privacy
Data interoperability
Interoperability is key to achieving the transformational goals in healthcare and life sciences for everything from telemedicine to virtual trials to app-based healthcare ecosystems.
Near real-time decisions
Once your data is harmonized, unlock its value with analytics and AI. Make smart, near real-time decisions that can help you reach your business goals and improve health outcomes of patients and communities
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Linear
sentese
Face detection
Detect faces, their position and expressions with deep analysis
Nudity detection
Detect raw and partial nudity and filter uploads on images & videos
Weapons, alcohol, & drugs
Proatively detect weapons, violence and inappropriate content.
Celebrities
Detect and recognize celebrities on images & videos.
Search
Block scammers and prevent fake profile pic uploads.
Minors detection
Detect babies, children, and teenagers under 18 to enhance safety.
Sentiment analysis
Understand the overall opinion, feeling, or attitude sentiment expressed in a block of text.
Syntax analysis
Extract tokens and sentences, identify parts of speech and create dependency parse trees for each sentence.
Entity analysis
Identify entities within documents and label them.
Content classification
Classify documents in 700+ predefined categories.
Multi-language
Enables you to easily analyze text in multiple languages.
Spatial structure understanding
Use the structure and layout information in PDFs to improve custom entity extraction performance.
Cloud Speech-To-Text
Accurately convert speech into text using an API powered by Google’s AI technologies.
Cloud Text-To-Speech
Convert text into natural-sounding speech using an API powered by Google’s AI technologies.
Video Caption & audio generation
Generate captions or translated audio for your video content automatically in any supported language
Automatic text translation
Real-time text translations for cross-language communication
Multi-language chat
Chat with users in different languages with automatic translation
Real-time audio translation
Easy captions and language translation for your audio content.
Face detection
Detect faces, their position and expressions with deep analysis
Nudity detection
Detect raw and partial nudity and filter uploads on images & videos
Weapons, alcohol, & drugs
Proatively detect weapons, violence and inappropriate content.
Celebrities
Detect and recognize celebrities on images & videos.
Search
Block scammers and prevent fake profile pic uploads.
Minors detection
Detect babies, children, and teenagers under 18 to enhance safety.
Data discovery and classification
Harness gives you the power to scan, discover, classify, and report on data from virtually anywhere.
Automatically mask your data to safely unlock more of the cloud
Built in tools to classify, mask, tokenize, and transform sensitive elements to help you better manage the data that you collect, store, or use for business or analytics.
Simple and powerful redaction
De-identify your data: redact, mask, tokenize, and transform text and images to help ensure data privacy.
Secure data handling
The Data Loss API runs on Google Cloud, your data securely and undergoes several independent third-party audits to test for data safety, privacy, and security.
Custom rules
Add your own custom types, adjust detection thresholds, and create detection rules to fit your needs and reduce noise.
Advanced AI
Improve your call/chat containment rate with the latest BERT-based natural language understanding (NLU) models.
State-based data models
Reuse intents, intuitively define transitions and data conditions, and handle supplemental question.
End-to-end management
Take care of all your agent management needs including CI/CD, analytics, experiments, and bot evaluation inside Dialogflow
Visual flow builder
Reduce development time with interactive flow visualizations that allow builders to quickly see, understand, edit, and share their work.
Omnichannel implementation
Build once, deploy everywhere—in your contact centers and digital channels. Seamlessly integrate your agents across platforms
Machine learning is an application of Artificial Intelligence (AI) that enables systems to automatically learn and improve from experience without human intervention through manual programming. Much like future-forward movies in the 90s, machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
In machine learning, computers learn through observations or data, such as examples, direct experience, or instruction. They use this information to extract patterns in data and make better decisions in the future based on the examples that are provided. The main aim is to allow computers to learn automatically without any human intervention or assistance and to adapt accordingly.
Products
Cloud Storage, Dataprep, Dataflow, DataProc, BigQuery, AI Hub, Data Labeling, Deep Learning VM, AI Platform, TensorFlow Tool, AI Prediction Platform

The Machine Learning algorithm used by Netflix allows it to recommend personalized TV shows and movies to subscribers.
“AutoML, Google’s AI that helps the company create other AIs for new projects, learned to replicate itself in October of 2017".
You can have machine learning without sophisticated algorithms, but not without good data.
Identification is the foundation of machine learning use cases. It tends to be most helpful in workflow routing, auto-tagging, and trend analysis use cases: knowing what something is is the first step in deciding what to do with it. credit
Examples
This involves combining multiple classifications and making them relate to each other. credit
Examples
Now, we start to add contextual clues. Clues specific to that specific company or time or geography. We’re not just labeling one aspect of one feature; we’re generating a sense of urgency, ranking, and prioritization. credit
Examples
At Level 4, we begin to incorporate AI/ML outputs into business workflows. The system has returned some sort of output (“this bank transaction is 91.7% likely to be fraudulent”), but deciding what to do with that output is where it gets really valuable (“cover up to $10,000 in fraudulent charges”). credit
Examples
Prediction is the golden ticket of artificial intelligence. The holy grail. And I sometimes to refer to this as the “last column” problem. In each case, you want to analyze all of the factors (e.g., age, farm size, satellite images, customer emails) to best predict the last column of your spreadsheet.credit
Examples
BigQuery ML lets you create and execute machine learning models in BigQuery using standard SQL queries. BigQuery ML democratizes machine learning by letting SQL practitioners build models using existing SQL tools and skills. BigQuery ML increases development speed by eliminating the need to move data.
A model in BigQuery ML represents what an ML system has learned from the training data. BigQuery ML supports the following types of models: 1
Linear regression
for forecasting; for example, the sales of an item on a given day. Labels are real-valued (they cannot be +/- infinity or NaN).
Binary logistic regression
for classification; for example, determining whether a customer will make a purchase. Labels must only have two possible values.
Multiclass logistic regression
for classification. These models can be used to predict multiple possible values such as whether an input is "low-value," "medium-value," or "high-value." Labels can have up to 50 unique values.
TensorFlow model importing.
This feature lets you create BigQuery ML models from previously trained TensorFlow models, then perform prediction in BigQuery ML.
Autoencoder
for creating Tensorflow-based BigQuery ML models with the support of sparse data representations.
K-means clustering
K-means is an unsupervised learning technique, so model training does not require labels nor split data for training or evaluation.
Multiclass logistic regression
These models can be used to predict multiple possible values such as whether an input is "low-value," "medium-value," or "high-value."
Matrix Factorization
You can create product recommendations using historical customer behavior, transactions, and product ratings and then use those recommendations for personalized customer experiences.
Time series
You can use this feature to create millions of time series models and use them for forecasting.
TensorFlow model importing.
This feature lets you create BigQuery ML models from previously trained TensorFlow models, then perform prediction in BigQuery ML.
Boosted Tree
for creating XGBoost based classification and regression models.
Deep Neural Network (DNN)
for creating TensorFlow-based Deep Neural Networks for classification and regression models.
AutoML Tables
to create best-in-class models without feature engineering or model selection.
AutoML enables developers with limited machine learning expertise to train high-quality models specific to their business needs. Build your own custom machine learning model in minutes.
Vertex AI
Unified platform to help you build, deploy and scale more AI models. Prepare and store your datasets Access the ML tools that power Google. Experiment and deploy more models faster. Manage your models with confidence
AutoML Vision
Derive insights from object detection and image classification, in the cloud or at the edge. Use REST and RPC APIs, Detect objects, where they are, and how many. Classify images using custom labels. Deploy ML models at the edge
AutoML Video Intelligence
Enable powerful content discovery and engaging video experiences. Annotate video using custom labels. Streaming video analysis. Shot change detection. Object detection and tracking
AutoML Natural Language
Reveal the structure and meaning of text through machine learning. Integrated REST API. Custom entity extraction. Custom sentiment analysis. Large dataset support
AutoML Translation
Dynamically detect and translate between languages. Integrated REST and gRPC APIs, Supports 50 language pairs. Translate with custom models.
AutoML Tables (beta)
Automatically build and deploy state-of-the-art machine learning models on structured data. Handles wide range of tabular data primitives. Easy to build models. Easy to deploy and scale models
Data Science is a blend of various tools, algorithms, and machine learning principles with the goal to discover hidden patterns from the raw data. Data Science is the scientific analysis of unstructured data for making it meaningful for developing strategies. These frequently asked questions are made up of queries that I get asked often.
Products
Pub/Sub, Dataflow, BigQuery, BQ BI Engine, Looker, Data Studio
With this much data available to analyse, access and implement, there is a science needed to mould them into reports or strategies.
Nearly 80% of data available over the internet is unstructured.
“7x – the number of times your business can scale faster.”.
Software as a Service (SaaS) are applications Web or mobile based systems that run in the cloud and customers can easily access and enjoy them without any product installations or update maintenance. Think of youTube, Netflix and other online services.
Leveraging Laravel Web Framework, I built RUGGED SAAS as an way to provide businesses a fast, managed services experience where we design, build, deploy and manage a product leveraging the same building blocks that our own products are built on for rapid development and a faster go to market on a subscription basis. This is the perfect start for your next great idea 🚀
If your business doesn’t rely on SaaS to solve problems, build revenue or track capital, then you will lose a lot
Businesses today use an average of 80 IT-sanctioned SaaS apps, a 5x increase in just three years and a 10x increase since 2015.
80% of workers admit to using SaaS applications at work without getting approval from IT.
Authentication
Authentication, registration, and password reset are ready out of the box.
Emails
Transactional and service emails out of the box and ready for your design inputs.
Invite System
Organize into teams and collaborate with others to build the next big thing.
Encrypted passwords
System wide data encrpytion starting with your user's password.
2-factor Sign In
Extra extra layer of authentication security with email and text confirmation codes.
Registration confirmation
Require your users to confirm their email address before using the site
Recurring subscription
Super simple subscription billing without the hassle with monthly and yearly plans
Braintree Integration
Your users payment information never touches our servers! All the validation is handled by Braintree Payments, a trusted payments service processor.
Invoices
Allow your customers to download PDF copies of their invoices.
Trial periods
Trial period settings from limited to unlimited days for your special users
Single charges
Enable a "one-time" charge to your subscribed users with an accompanying invoice.
Team billing
Enable teams to have their own billing and manage each team member's subscription easily.
Secure site
Every application receives a free, auto-renewing SSL certificate during deployment.
Data Encryption
Triple layer encryption starting the Cloud infrastructure, application and data layer
Login throttle
Prevent brut force logins with automatic throttling and cooling period before retries.
Automatic backup
Scheduled backups of application and database that run like clock-work.
Security emails
Immediately your users of important security changes via email with reversal options.
Impersonation
Need to login as one of your user? Impersonate allows you to authenticate as any of your customers.
Metrics
RuggedSaaS provides beautiful charts showing you the throughput and peformance of your application.
User management
Manage users, register new ones, analyze logins, review reports and handle blocked users.
Site configurations
Manage everything from enabling/disabling registration to turning key features on and off.
Announcements
Easily create announncements with disappearing timers so that your users so they are always in the loop.
Application Events
Gain x-ray views logins, uploads, registrations, system updates, changes, and other events
Face detection
Detect faces, their position and expressions with deep analysis
Nudity detection
Detect raw and partial nudity and filter uploads on images & videos
Weapons, alcohol, & drugs
Proatively detect weapons, violence and inappropriate content.
Celebrities
Detect and recognize celebrities on images & videos.
Search
Block scammers and prevent fake profile pic uploads.
Minors detection
Detect babies, children, and teenagers under 18 to enhance safety.
Backups
Scheduled backups of application and database that run like clock-work
Cronjobs
Easily start and manage supervised Laravel Queue workers directly
Storage
Easily stream your file uploads directly to S3 like magic.
Queues
Increased application performance with queues abstraction and processing.
Error logging
Crystal clear insights and details of every error generated in your envrionments.
Monitoring
We monitor a variety of metrics about your applications, databases, and caches.
Derive insights from the images in the cloud or at the edge with AutoML Vision or use pre-trained Vision API models to detect emotion, understand text, and more.
AutoML enables developers with limited machine learning expertise to train high-quality models specific to their business needs. Build your own custom machine learning model in minutes.
Explainable AI is a set of tools and frameworks to help you understand and interpret predictions made by your machine learning models, natively integrated with a number of Google's products and services
BigQuery ML lets you create and execute machine learning models in BigQuery using standard SQL queries. BigQuery ML democratizes machine learning by letting SQL practitioners build models using existing SQL tools and skills. BigQuery ML increases development speed by eliminating the need to move data. Supported algorithms on BQML are:
Regression & Classification
Linear & Logistic Regression: for forecasting; for example, the sales of an item on a given day. Labels are real-valued (they cannot be +/- infinity or NaN).
Binary logistic regression
for classification; for example, determining whether a customer will
make a purchase. Labels must only have two possible values.
Multiclass logistic regression for classification.
These models can be used to predict multiple possible values such as
whether an input is "low-value," "medium-value,"
or "high-value." Labels can have up to 50 unique values.
In BigQuery ML, multiclass logistic regression training uses a
multinomial classifier with a cross-entropy loss function.
Boosted Trees
Boosted Tree for creating XGBoost based classification and
regression models.
Deep Neural Networks
Deep Neural Network (DNN) for creating TensorFlow-based Deep Neural
Networks for classification and regression models.
Wide-and-Deep Networks
AutoML Table Models
Used to create best-in-class models without feature engineering or
model selection. AutoML Tables searches through a variety of model
architectures to decide the best model.
Clustering
K-Means:
K-means clustering for data segmentation; for example, identifying
customer segments. an unsupervised learning technique, so model
training does not require labels nor split data for training or
evaluation
Dimensionality Reduction
PCA:
Autoencoder:
Used for creating Tensorflow-based BigQuery ML models with the
support of sparse data representations. The models can be used in
BigQuery ML for tasks such as unsupervised anomaly detection and
non-linear dimensionality reduction.
Collaborative Filtering
Matrix Factorization
Used for creating product recommendation systems. You can create
product recommendations using historical customer behavior,
transactions, and product ratings and then use those recommendations
for personalized customer experiences.
Time Series Forecasting
ARIMA+
Time series for performing time-series forecasts. You can use this
feature to create millions of time series models and use them for
forecasting. The model automatically handles anomalies, seasonality,
and holidays.
Importing Models
TensorFlow Models:
TensorFlow model importing. This feature lets you create BigQuery ML
models from previously trained TensorFlow models, then perform
prediction in BigQuery ML.
Post
Create posts, share content, comment, reply and upload your videos and photos.
Forums
Join the discussion to ask questions, share insights, and discuss topics.
Follows
Super simple follows and connections for users ready out of the box
Notifications
You'll fall in love with the sleek, notification bubbles that pop and disappear like magic
Meetups
Turn your online friends into real-life buddies with super simple meetups
Chat & conversations
Start group chats, invite new participants and message in a really fun way.